 Prose rules ask the agent to behave. Structure makes the wrong action physically unavailable. Photo by Andrej Lišakov on Unsplash.
Prose rules ask the agent to behave. Structure makes the wrong action physically unavailable. Photo by Andrej Lišakov on Unsplash.
I spent two weeks instrumenting the agents that do QA work on my personal trading research repo. Every tool call is logged. Every run is audited by another agent. Every waste pattern is categorized and counted.
The short version: I took my QA agent from 67% wasted tool calls down to a 16–20% floor across six epics. Almost none of the improvement came from better prompts. The wins that stuck were structural — deny rules, phase gates, hook-based guards, and eventually an architectural split into two agents with a file as the interface contract.
The agent is not stupid. It is uncertain. When it’s uncertain, it reaches for tools. If the wrong tool is reachable, it will eventually reach for it. Your job as the operator is less about writing the right words and more about making the wrong tool physically unavailable. That’s the frame for everything that follows.
Waste percentage is the headline metric. What I was actually buying is two things: predictable agent behavior — I can say before a run what the agent will and won’t do — and efficient completion in calls, time, and API spend. The waste number is a proxy for both. Structural enforcement delivers them together; prose rules deliver neither reliably.
This is not a benchmark study. It’s a small personal experiment with ~60 runs across one orchestrator. But the progression is specific enough that I think it generalizes: prose rules don’t survive agent uncertainty; structure does.
The setup
QuantWorkstation is my research harness. Stories live as markdown files in
epics/. An orchestrator (run-epic) spawns agents — lead-engineer writes
code, qa-engineer verifies it, lint-mechanic fixes any remaining style issues.
Every spawn writes a JSONL trace via a PostToolUse hook. After each run a
qa-auditor agent reads the trace and scores it: how many calls were
necessary, how many were wasted, what pattern the waste fell under.
The scoring is the thing that makes this exercise possible. Without per-call categorization, “my agent got better” is vibes. With it, I can say which pattern got shorter and which fix closed it.
The trend
 Waste % averaged across epic, QA agent only.
Waste % averaged across epic, QA agent only.
Two things to notice. First,
the drop from the 27–32% band to the 16–20% band is real, and it’s held for
three consecutive epics — that’s the -11pp result. Second — and this is the
part most agent-tuning posts don’t tell you — the dominant waste pattern
changed between the two bands. Early waste was grep-storm and file-reread:
the agent re-reading files it already had and issuing broad searches with no
file anchor. Late waste is scope-archaeology and file-discovery: calls
spent confirming story boundaries, or one-time-orientation cost on new
modules. That’s qualitatively lower-severity waste — not sloppiness, a
genuine “I don’t know where this is yet.” The numbers got better. The kind
of waste got better too.
What I tried first (and why it didn’t stick)
The obvious move is “write tighter prompts.” I spent a lot of the early runs doing exactly this.
Examples of rules I added to the qa-engineer command file:
- “Filter lint output ONCE. Do not re-run
make lint.” - “Do not grep files you already know exist — Read them directly.”
- “Do not
lsthe epics directory after reading INDEX.md.” - “Maximum 2
make lintruns per session.” - A literal “STOP GATE” block at the end of Phase 2.
Every one of these got ignored at some point. The common assumption is that prose rules fail because small models can’t follow them. My data says otherwise. Both of these agents are Sonnet:
- qa-engineer, run 13: agent completed the prescribed Phase 2 algorithm correctly, reached the prose STOP GATE, then launched an 11-call re-investigation. Waste jumped from 13% (previous run) to 42%.
- lead-engineer, R6: memory contained “max 2 cycles, batch fix” for mypy.
Agent ran
make typecheck, then re-ran mypy on five individual files. Seven wasted calls, rule ignored.
Prose STOP has now failed on Sonnet 4 out of 4 times I’ve observed it. This is not a Haiku problem. It’s a structural problem.
The failure mode is mechanical. Prose rules tell the agent what not to do. When the agent is uncertain about what to do, “don’t do X” leaves an infinite space of Y’s to try. Under that pressure the agent reaches for whatever tool looks adjacent to the problem, and adjacent-looking often means the exact thing the rule was meant to prevent.
This is why “waste percentage” is a proxy, not the goal. What I’m actually measuring is the gap between what I intended the agent to do and what it did. Prose leaves that gap open — the agent closes it when it’s sure, doesn’t when it isn’t. Structural enforcement closes it mechanically: a tool that’s denied at the permission layer cannot be called, period. That’s the move that produces both outcomes at once — predictable behavior (the space is bounded) and efficient completion (the bounded space has fewer wrong paths to spend calls on).
What actually moved the number
Three categories of fix accounted for almost all the improvement.
1. Seed the answer, not the rule.
Instead of “filter lint output once,” the command file now contains the exact grep command, copy-paste ready, with a note on the expected output format. Instead of “find the test for story X,” the command file has a story → file table. This is boring and it works. The agent doesn’t have to reason about how to filter, so it doesn’t have space to reason its way into the wrong filter.
The highest-leverage version of this pattern is replacing prose procedures
with shell scripts and Makefile targets. The command file stops saying “do
these seven things in this order” and starts saying “run make arm-qa-gate.”
The sequencing, the error handling, the idempotency — all of it lives in the
script, where it’s deterministic. The agent’s job collapses to invoking the
right target at the right step.
A few examples from this codebase:
make prime-agent— clears read trackers, writes the current-command sentinel, arms the trace writer. Six shell operations behind one name. Before this existed, agents sometimes reached their first tool call before the sentinel was in place and guards fired against main-session paths.make arm-qa-gate/make arm-le-gate— writes the HARD STOP sentinel at the terminal step of a command file. One line in the command file replaces a prose “now stop and do not continue” that Sonnet ignored 4 times.make commit-push-qa— encapsulates the git flow for agent code completion: stage exactly the files QA touched, lint-check the staged diff, run the commit-message linter, push to the feature branch. Agents that drop down to rawgit add/git commit/git pushregularly stage the wrong files, skip the lint pre-check, or commit lint-only changes when the step says skip. With the Make target, there is one path, and the path enforces versioning discipline automatically.
The pattern in all three: the command file says what (run this target), not how (here’s a seven-line procedure). Prose procedures rot — the agent skips steps under uncertainty. Shell scripts execute atomically and return a pass/fail signal the agent can’t argue with.
When a prose constraint failed twice, I stopped rewording it and replaced it with a recipe. When a multi-step procedure failed twice, I stopped writing steps and wrote a Make target.
2. Deny by hook, not by prompt.
.claude/settings.json has a deny list. ruff, python -m ruff, direct
grep piped through sed, inline python3 -c — all blocked at the
permission layer. The agent can’t violate them because the tool call is
rejected before it runs.
The cleanest example of why this matters is the bypass chain I watched unfold
over several runs. The original problem was sequential chunk-reading of large
files. I deployed a PreToolUse Read guard that caps re-reads at two. Here’s
what happened next:
- Read guard lands. Agent can no longer chunk-read with the Read tool.
- Agent switches to
sed -n '1,100p' file.py. 20 wasted calls in lead-engineer R6 before I noticed. - I add
sed/awk/head/tailon source files to the Bash guard. - Agent switches to
cp file.py /tmp/snapshot.py && Read /tmp/snapshot.py. New path, tracker doesn’t match the renamed file. - I add a snapshot detector that strips
_snapshot/_backup/_copy/_orig/_tmpsuffixes and charges the tracker against the original filename. - Agent switches to
python3 -c "print(open(f).read())". Last route. python3 -candpython3 <<go in the settings.json deny list.
One behavior — “I don’t know where the target is, so I’ll read everything” — and five bypass routes to the same effect. Every prompt-level rule (“do not chunk-read”) would have been trivially defeated. Every guard that closed one route exposed the next. The right model is not “ban this tool” but “cover all paths to the bad behavior, because the agent will probe them.”
That said, deny-by-hook has a real failure mode, and I hit it. In run 8, the qa-engineer’s command file prescribed a grep-pipe recipe that the permission allowlist didn’t match. The permission system rejected the call — correctly, by its own rules — and the agent cascaded into 12 fallback greps trying to reconstruct what the recipe was supposed to do. 24% waste caused entirely by a guard being too strict for a legitimate recipe.
More guards are not automatically safer. A guard that blocks a valid action the agent has been told to take is a waste amplifier. The fix is to simplify the recipe until it matches a single permission pattern, not to add more guards.
3. Phase gates with sentinel files.
Prose ordering (“do X, then Y”) is brittle. A phase gate isn’t:
- Phase A: agent can Read, Grep, Edit. Cannot Bash.
- Phase B: agent can Bash(
make lint) and Read the result. Cannot Edit. - A sentinel file in
/tmp/marks the transition.
The agent physically cannot run lint before editing, because the tool
permission set for Phase A doesn’t include it. This killed the
“pre-fix lint scoping” pattern completely — lint-mechanic went from running
make lint before editing 100% of the time to 0%.
Phase gates are also where the STOP GATE mechanism lives: after Phase 2,
the command file reaches a hard stop. Early versions of this were prose (“do
not investigate further after Phase 2”). Those got ignored — 4 out of 4
consecutive runs on Sonnet. The version that worked is a sentinel file:
make arm-qa-gate runs touch /tmp/agent-qa-epic-done.txt, and a
PreToolUse hook checks for that file on every subsequent tool call and
exits 2 if it exists. The labelled section in the command file is
documentation. The sentinel is enforcement. The hook is the line the agent
cannot cross.
The architectural move
At some point, even with all of the above, qa-engineer was still spending 4–7 calls on a lint fix-verify loop — edit one error, run lint, edit the next error, run lint again. Two distinct jobs, one agent, and the agent was good at neither.
So I split it. qa-engineer now identifies issues and writes a fixlist —
a file in /tmp/ listing {file, line, code, description} for every error
to fix. It then spawns lint-mechanic (running on Haiku, because the work is
mechanical), which reads the fixlist and applies edits. The fixlist is the
interface contract. Neither agent needs to share state with the other beyond
the file.
This is more of a compiler than a conversation. It’s also the first thing
that reliably cleared the lint fix-verify loop, because the two agents now
have incompatible tool sets — qa-engineer can’t run make lint, and
lint-mechanic can’t write a fixlist. They physically cannot do each other’s
jobs.
But — and this is the honest part — the split didn’t make waste go away. It relocated it.
 Lint-mechanic’s first six runs on Haiku.
Lint-mechanic’s first six runs on Haiku.
Haiku introduced its own failure
class: dropping the middle segment of a 3-part pipe (cmd | tee file | tail
→ cmd | tail). Without tee, no file to read, so the agent re-runs make lint to check the result — each time dropping tee again, each re-run
making the budget worse. A WARNING block in the command file didn’t fix
it. What fixed it was moving the canonical command to the Rules section of
the agent definition, because Haiku reads Rules proactively as a decision
filter but reads process steps reactively during execution — by the time it
reaches a step, it has already committed to a command form. One caveat on
this table: n=6. A single bad run (run 5 at 64%, driven by one
pipe-simplification bug) pulls the average around hard. The tee-drop pattern
is real and recurred across three runs, but I wouldn’t read these waste
percentages as a trend — they’re individual data points.
There’s also a cost argument I stopped fighting. Haiku is cheap enough per call that lint-mechanic’s absolute dollar waste is trivial even at 50%. qa-engineer runs Sonnet and does 30–70 calls per run, so cutting its waste by 10pp is real money. lint-mechanic runs Haiku and does 5–11 calls per run, so further optimization buys pennies. At some point the engineering time to hunt down the last Haiku quirk stops being worth it — the whole reason I split work onto Haiku in the first place was that it’s cheap enough to be “good enough.” Optimization on a Haiku agent has an economic floor that doesn’t apply to Sonnet.
I did not know the tee-drop pattern before I started. I don’t think you can predict it from first principles. You find it by running the agent 5 times and noticing the same deviation.
The economics
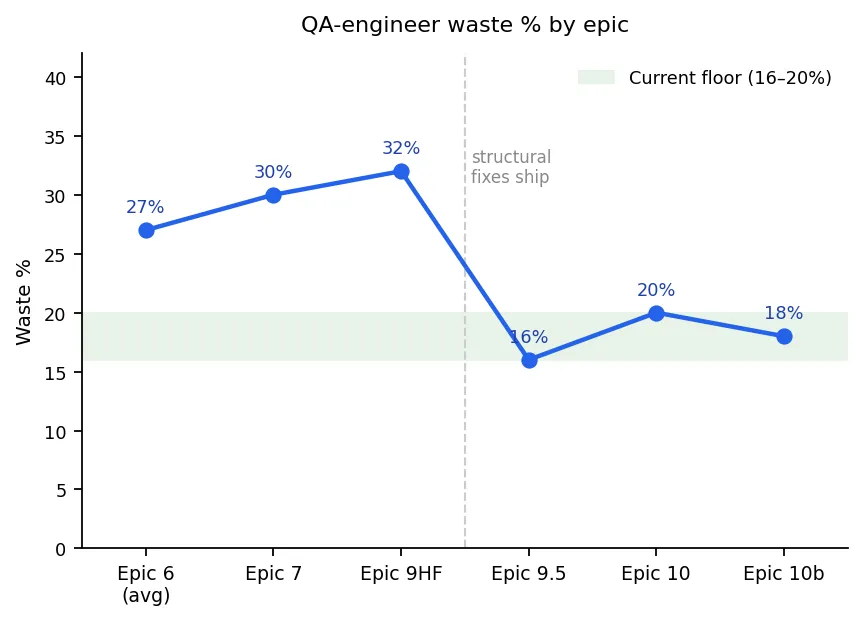 QA-engineer waste % by epic — dropping from 27–32% in Epics 6/7/9HF down to a 16–20% floor in Epics 9.5, 10, and 10b after structural fixes shipped.
The waste metric is useful for tuning, but it also has a direct cost
interpretation. Model it simply: each tool call has unit cost C = 1. Every
call is either required (r) or wasted (w), where r + w = 1. At 67% waste —
the baseline — required calls represent 33% of total spend. At 18% waste,
they represent 82%.
QA-engineer waste % by epic — dropping from 27–32% in Epics 6/7/9HF down to a 16–20% floor in Epics 9.5, 10, and 10b after structural fixes shipped.
The waste metric is useful for tuning, but it also has a direct cost
interpretation. Model it simply: each tool call has unit cost C = 1. Every
call is either required (r) or wasted (w), where r + w = 1. At 67% waste —
the baseline — required calls represent 33% of total spend. At 18% waste,
they represent 82%.
For a story of equivalent complexity:
cost ratio = r_baseline / r_current = 0.33 / 0.82 ≈ 0.40An outcome that cost $1.00 at baseline costs ~$0.40 now — about 60% cheaper per outcome.
Three assumptions behind this: (1) equal cost per call regardless of tool type, (2) $1 is a normalized unit, not a real dollar figure, and (3) required calls are constant for comparable scope. The third is the load-bearing one — required call count scales with story complexity, so the comparison only holds when scope is held fixed.
This is also why the pattern shift matters alongside the percentage. Eliminating grep-storms and post-stop rampages is different from cutting waste by writing tighter stories with less scope ambiguity. Both happened here, and a follow-up post will break down how much each drove.
What’s left
The 16–20% floor across epics 9.5 / 10 / 10b looks stable. The waste that remains falls into three buckets:
- Scope archaeology (structural, low severity): the agent confirming
“is this file in scope for this story.” Reducible by surfacing the
In Scope / Out of Scopesection of the story file in the agent’s prompt preamble. Not yet done. - File discovery (one-time cost): orientation on new modules. Not worth fixing — it’s a legitimate first-read.
- Model-level patterns: overlapping offset reads (agent reads lines 100–200, then 180–280), re-reading a file it already has in context. These aren’t addressable from outside the model. I don’t plan to fight them.
The lead-engineer CSV has a measurement gap — the auditor stopped writing
rows after Epic 9.5. Fixing that is the highest-value next move, because
without it I’m blind to whether my implementation agent is improving or
regressing.
The meta-lesson
If you’re tuning your own agents, the rough order I’d suggest is:
- Instrument first. If you can’t count waste per-call and categorize the
pattern, you are tuning blind. A
PostToolUsehook that dumps JSONL and an auditor that scores it are maybe a day’s work. - Seed answers before rules. When the agent freestyles, the fastest fix is to hand it the exact command it should have used. Replace prose prohibitions with recipes.
- Move permanent constraints into hooks or settings. Anything you find yourself writing “do not” about twice belongs in a deny list, a guard script, or a phase gate — not in a prompt.
- Split when one agent is doing two jobs. A fixlist (or any structured file) is a better interface between agents than shared conversational context.
- Accept that some waste is in the model. Don’t burn tuning hours on patterns that survive three structural fixes. Log them, move on.
The reason I think this generalizes past my setup: every fix that stuck was either enforced by the runtime (deny rules, hooks, phase permissions) or represented as a structured file (fixlists, sentinels, tables). Every fix that failed was a sentence in a prompt. The phase boundary between these two categories is pretty sharp.
That’s what I actually want: predictable behavior and predictable delivery. If you know exactly what an agent will do, you can trust the quality of what it produces. An agent whose behavior space you can’t describe is an agent whose output has to be re-audited from scratch every run.
The uncertainty framing at the top of this post is the reason structural enforcement works where prose doesn’t. Prose narrows the space of allowed actions by asking the agent to remember a constraint. Structure narrows it by making the wrong action physically unavailable. One depends on the agent; the other doesn’t.
This is part one of a series. Part two will cover the cost model in depth — how to price outcomes rather than calls, what the data shows about required-call variance across story complexity, and what rebuilding lead-engineer measurement coverage reveals about the full-system picture.
Data for this post: 27 rows in docs/agent-metrics/qa_runs.csv, 8 waste
pattern writeups in docs/agent-metrics/patterns/pattern_*.md. Running
period: April 11–13, 2026. One orchestrator, one repo. See
github.com/william-burks/QuantWorkstation.